The term computer graphics has been used in a broad sense to describe "almost everything on computers that is not text or sound”. Typically, the term computer graphics refers to several different things:
- the representation and manipulation of image data by a computer
- the various technologies used to create and manipulate images
- the sub-field of computer science which studies methods for digitally synthesizing and manipulating visual content, see study of computer graphics
Computer graphics is widespread today. Computer imagery is found on television, in newspapers, for example in weather reports, or for example in all kinds of medical investigation and surgical procedures. A well-constructed graph can present complex statistics in a form that is easier to understand and interpret. In the media "such graphs are used to illustrate papers, reports, thesis", and other presentation material.
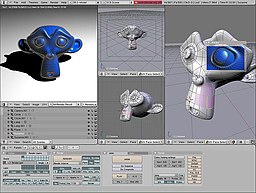
Many powerful tools have been developed to visualize data. Computer generated imagery can be categorized into several different types: 2D, 3D, and animated graphics. As technology has improved, 3D computer graphics have become more common, but 2D computer graphics are still widely used. Computer graphics has emerged as a sub-field of computer science which studies methods for digitally synthesizing and manipulating visual content. Over the past decade, other specialized fields have been developed like information visualization, and scientific visualization more concerned with "the visualization of three dimensional phenomena (architectural, meteorological, medical, biological, etc.), where the emphasis is on realistic renderings of volumes, surfaces, illumination sources, and so forth, perhaps with a dynamic (time) component"
Reference links
Computer graphics programs can be downloaded from http://www.w3professors.com/Pages/Courses/Computer-Graphics/Programs/CG-Program.html














 The word is originally derived from the Latin optimum, meaning "best." Being optimistic, in the typical sense of the word, ultimately means one expects the best possible outcome from any given situation. This is usually referred to in psychology as dispositional optimism. Researchers sometimes operationalize the term differently depending on their research, however. For example, Martin Seligman and his fellow researchers define it in terms of explanatory style, which is based on the way one explains life events. As for any trait characteristic, there are several ways to evaluate optimism, such as various forms of the Life Orientation Test, for the original definition of optimism, or the Attributional Style Questionnaire designed to test optimism in terms of explanatory style.
The word is originally derived from the Latin optimum, meaning "best." Being optimistic, in the typical sense of the word, ultimately means one expects the best possible outcome from any given situation. This is usually referred to in psychology as dispositional optimism. Researchers sometimes operationalize the term differently depending on their research, however. For example, Martin Seligman and his fellow researchers define it in terms of explanatory style, which is based on the way one explains life events. As for any trait characteristic, there are several ways to evaluate optimism, such as various forms of the Life Orientation Test, for the original definition of optimism, or the Attributional Style Questionnaire designed to test optimism in terms of explanatory style. 

{kind=link}